

Tác giả: Phong TN
I have 10+ years of experience working as a software engineer with more than 4 years of experience as software architecture.
My addiction to the experience in the design and operation of systems capable of instant expansion, high availability with resources efficiently.
How to tracking Architectural Decisions?
Một trong những thứ khó theo dõi nhất trong suốt vòng đời của một dự án là nguyên nhân đằng sau những quyết định kỹ thuật quan trọng. Một người mới tham gia dự án có thể cảm thấy bối rối, tức giận hoặc cảm thấy khó hiểu vì một số quyết định trong quá khứ. Đây là lúc họ sẽ muốn tìm đến Architectural Decision Records (ADRs).
Vậy ADRs là gì?
Xin được trích dẫn lời cụ Michael Nygard cho có vẻ nguy hiểm.“An architecture decision record is a short text file in a format similar to an pattern that describes a set of forces and a single decision in response to those forces.” Documenting Architecture Decisions by Michael Nygard
Một ADR thông thường là 1 file text ngắn (1 or 2 trang) trình bầy ngữ cảnh, mô tả một quyết định kiến trúc cụ thể và mức độ ảnh hưởng của quyết định này đến hệ thống.
Nội dung một ADR bao gồm những gì?
Title: Nên ngắn gọn. VD: Sử dụng Nginx làm HTTP server.
Decision: Chúng tôi quyết định sử dụng Nginx làm HTTP server thay thế cho Apache web server.
Status: proposed, accepted or superseded.
Context: Trình bầy ngữ cảnh dẫn đến quyết định này?
Consequences: Mức độ ảnh hưởng của quyết định này là gì?, bao gồm cả lợi và hại.
Những lợi ích khi có ADRs?
Đối với thành viên mới: Các thành viên mới join team có thể xem lại lịch sử của các quyết định kiến trúc quan trọng, nhanh chóng theo kịp tốc độ về kiến trúc hiện tại và lý do tại sao một quyết định được đưa ra, và những tác động của quyết định đó.
Ví dụ: tháng 8 năm 2019 hệ thống gặp vấn đề lớn về hiệu năng, team dự án đề xuất áp dụng kiến trúc microservice cho dự án. Tuy nhiên sau 1 sprint làm thử nghiệm và đánh giá chúng tôi nhận thấy áp dụng kiến trúc mới có thể làm tăng chi phí hạ tầng lên gấp n lần. Chúng tôi đã quyết định giữ nguyên kiến trúc hiện tại.
Chuyển giao hệ thống, giúp đơn giản hoá các bước chuyển giao: SA, Technical lead, DevOps engineering…có thể nhanh chóng nắm bắt được kiến trúc và lý do tại sao kiến trúc của hệ thống phát triển như hiện tại chỉ đơn giản bằng cách đọc qua các ADR.
Chia sẻ: Theo thời gian những quyết định kiến trúc quan trọng là tài nguyên có thể được chia sẽ qua các dự án khác nhau dưới dạng ADRs.
Tố chức lưu trữ ADRs như nào?
Sử dụng Git repository để lưu ADRs như một thư mục cùng với source code của dự án. Dùng adr-tool để nhanh chóng tạo ADR

Kiểm tra nền tảng Aerobic với bài test Cooper
Kiểm tra sức bền là một cách để đo lường hiệu quả của hệ tuần hoàn và hệ hô hấp của cơ thể trong việc cung cấp oxy cho các cơ bắp và hỗ trợ các hoạt động thể chất.
Việc đánh giá đúng thể trạng hiện tại sẽ giúp bạn hiểu rõ cơ thể mình hơn cũng như đưa ra kế hoạch tập luyện tốt hơn.
Xin được giới thiệu một bài kiểm tra thể lực đơn giản, được phát triển bởi tiến sỹ, bác sỹ y khoa Kenneth Cooper, từ cách đây hơn 50 năm.
Bài test ra đời với mục đích nhanh chóng đánh giá được thể trạng của binh sỹ Mỹ trong thời kỳ chiến tranh lạnh.
Hiện đây vẫn là bài test thể lực cơ bản được sử dụng trong quân đội.
CÁCH THỨC THỰC HIỆN NHƯ SAU:
Đồng hồ GPS hoặc điện thoại có cài Strava.
Tìm khu vực rộng rãi (sân vận động, công viên, quảng trường…)
1. Khởi động làm nóng, chạy nhẹ 10 phút.
2. Chạy hết sức trong 12 phút.
3. Kiểm tra quãng đường đã chạy được, so sánh kết quả với bảng bên dưới.


Kết quả bài test giúp đánh giá thể trạng sức bền (aerobic) hiện tại cũng như ước tính được VO2Max.
VO2 Max là chỉ số thể hiện lượng oxy tối đa mà cơ thể có thể vận chuyển được trong 1 phút (ml/kg/min) trong khi tập thể dục. VO2 Max càng cao đồng nghĩa với khả năng tim mạch cao, sức bền càng lớn.
Ăn gì sau tập?
Recovery là một phần quan trọng của bất kỳ chu trình tập luyện nào. Bao gồm chế độ dinh dưỡng hợp lý trong quá trình phục hồi sau tập luyện, ngủ, rolling hoặc massage, giãn cơ, tập luyện với cường độ thấp. Đặc biệt với mục tiêu tối đa hóa kết quả thu được từ bài tập chúng ta không nên bỏ qua việc bổ sung dinh dưỡng, vitamin cần thiết sau tập, khi mà cơ thể đang ở trạng thái “window of opportunity”, thời điểm mà cơ bắp dễ dàng tiếp thu năng lượng nhất.
Sau buổi tập, cơ bắp bị thiếu glycogen (dạng dự trữ của carbonhydrate), là chất cung cấp năng lượng cho sự vận động của cơ trong khi tập. Nếu chúng ta không ăn gì sau buổi tập dài, cơ thể đơn giản là bắt đầu tìm đến những gì sẵn có. Một khi đã dùng hết các nguồn dự trữ khác, cơ thể sẽ bắt đầu phân hoá protein. Lựa chọn tốt nhất là kết hợp các món ăn có protein tiêu hoá nhanh và carbohydrate dạng phức vì chúng sẽ hỗ trợ quá trình phát triển cơ và ngăn tình trạng xuống cơ (muscle loss). Mình đã trải qua tình trạng muscle loss sau khi chạy 100km tại VMM, do không nạp đủ dinh dưỡng nên sụt mất 1.5kg (không kể nước). Với body tương đối lean (ít mỡ) thì việc sụt 1.5kg chỉ sau 1 ngày nhìn rất kinh khủng và sẽ phải mất rất nhiều thời gian nữa mới build lại được phần cơ bắp này :(.
3 mục tiêu chính mà chu trình recovery cần đạt được là khôi phục cân bằng nước và điện giải, bổ sung dự trữ glycogen trong cơ bắp và gan, kích thích quá trình tổng hợp protein. Thực hiện việc này bằng cách bổ sung nước, carbohydrates, protein trong vòng 30-60 phút sau buổi tập. Điều này đặc biệt quan trọng với các bài tập tiêu hao lượng lớn glycogen, những bài tập dài hơn 2 giờ, bài tập với cường độ cao hoặc vận động viên có kế hoạch với nhiều bài tập trong ngày.
Tỉ trọng cần thiết là khoảng 3-4 phần carbonhydrate cùng với 1 phần protein. Natri giúp vận chuyển carbohydrates ra khỏi ruột đi vào máu, bổ sung 500-700mg natri cùng với khoảng 500ml nước cho mỗi 0.5kg trọng lượng cơ thể đã mất trong quá trình tập luyện.
Lượng carbohydrates cần tiêu thụ sau tập dựa trên trọng lượng cơ thể. Mức khuyến nghị khoảng 1-1.2g carbohydrates trên mỗi kg cân nặng. Lượng protein khuyến nghị vào khoảng 10-25gr.
Ví dụ về 1 bữa ăn sau tập cho vận động viên 70kg:
1 thìa cà phê dầu ô liu (5ml)
1-2g muối (1g muối chứa 400mg natri)
150g bánh mỳ hoa cúc harrys brioche (bẻ khoảng 3 miếng)
50g trứng gà (khoảng 1 quả lớn)
Thực đơn như trên chứa khoảng: 75g carbonhydrate, 20g protein, 20g fat, 800mg natri. Tổng cộng > 500 calories.

Chú ý:
Mặc dù đây là thực đơn cơ bản về một bữa ăn sau tập tuy nhiên có rất ít bằng chứng cho thấy việc ăn ngay sau tập là cần thiết đối với các vận động viên sức bền. Điều này phụ thuộc rất nhiều vào bài tập, cường độ, thời gian tập luyện. Chi tiết có thể tham khảo thêm tại đây.
Bất kể bạn tập luyện bao nhiêu, tổng lượng calories, carbs, protein, fat ăn trong ngày quan trọng hơn nhiều so với thời điểm ăn.
Kafka Note
Topic Partitions
Kafka chia nhỏ topic thành các partitions. Mỗi bản ghi (message) luôn bao gồm key-value, lưu trữ trong một partition dựa vào key của bản ghi đó. Với bản ghi không có key (key null) Kafka tự động áp dụng cơ chế round-robin để phân bổ bản ghi đến partition. Nếu Producer không chỉ rõ partition nào lưu giữ bản ghi thì broker sẽ sử dụng key để quyết định partition sẽ lưu giữ bản ghi đó.
Kafka sử dụng partitions để mở rộng một topic ra nhiều servers khác nhau. Cơ chế này đảm bảo Kafka có thể phục vụ số lượng lớn các Producer cùng lúc gửi bản ghi đến Kafka. Cũng như cho phép Consumer consume đồng thời các bản ghi theo số lượng partitions hiện có.

Thứ tự của bản ghi được đảm bảo trong mỗi partition. Nếu các bản ghi có chung key thì toàn bộ bản ghi sẽ được lưu trữ trên cùng 1 partition, khá hữu dụng trong trường hợp cần lưu Relay Log.
Kafka Replication
Kafka cũng tự động replicate partitions tới nhiều brokers để đảm bảo khả năng chịu lỗi (failover).

Cơ chế replication của kafka đảm bảo rằng khi một bản ghi đã commit thì nếu leader lỗi thì leader mới được lựa chọn cũng sẽ có bản ghi đó.
Kafka đảm bảo điều này bằng việc chỉ lựa chọn leader mới từ 1 tập các bản sao (replicas) có trạng thái “in-sync” với leader trước đó hoặc nói một cách đơn giản là dựa theo leader’s log.
Leader của mỗi partition theo dõi quá trình in-sync của các bản sao (ISR) bằng việc tính toán độ trễ của mỗi bản sao với leader. Khi một bản ghi được gửi tới broker, nó được lưu lại bởi leader và đồng bộ tới toàn bộ các bản sao của partitions. Một bản ghi chỉ được coi là đã commit khi được sao chép thành công với toàn bộ các bản sao có trạng thái “in-sync”. Độ trễ của việc đồng bộ này sẽ bị ảnh hưởng bởi bản sao đồng bộ chậm nhất trong danh sánh bản sao “in-sync”. Do vậy việc quan trọng là phát hiện ra bản sao bị chậm và nhanh chóng xóa bỏ khỏi danh sách bản sao “in-sync”. Khi này bản sao đó sẽ rơi vào trạng thái “out-of-sync” và đương nhiên sẽ không thể được lựa chọn trong trường hợp leader bị lỗi.
Offsets and Consumer Position
Message lưu trữ trong partition sẽ đi kèm với 1 số ID tự tăng hay còn gọi là offset. Offset về bản chất là 1 dạng unique identifier của message trong partition đồng thời nó cũng thể hiện vị trí của consumer trong partition. Do vậy, nếu 1 consumer có vị trí 5 thì có nghĩa là consumer này đã consume hết những message có offset từ 0 đến 4, message kế tiếp nhận được sẽ có offset là 5.
Có 2 khái niệm về postion liên quan đến consumer cần nắm rõ:
position or current offset: vị trí của message kế tiếp consumer sẽ nhận được khi consume. Nó luôn lớn hơn offset lớn nhất của message mà consumer đã consume được trong partition. Nó sẽ tự động tăng mỗi khi consumer nhận được message thông qua phương thức poll(long) (Java Kafka Client Consumer).
commited position or commited offset: offset này thể hiện vị trí của message mà consumer đã xử lý xong. Lấy ví dụ: Consumer nhận được 20 message, consumer sẽ xử lý lần lượt từng message, sau khi xử lý xong message, consumer sẽ thông báo lại với Kafka offset của message đã xử lý. Consumer tự động commit offsets theo định kỳ hoặc developer có thể chủ động commit thông qua phương thức commitSync hoặc commitAsync.
committed position có ý nghĩa quan trọng khi partition rebalance. Khi một consumer crash hoặc một consumer mới join group sẽ kích hoạt sự kiện rebalance. Sau khi rebalance, mỗi consumer có thể sẽ được gán với một tập partitions mới. Lúc này consumer sẽ dựa vào committed position mới nhất của mỗi partition để xác định vị trí message sẽ consume.
Nếu committed position nhỏ hơn position thì message có offset nằm giữa committed position và position sẽ được xử lý lại, đồng nghĩa với việc những message này sẽ được xử lý 2 lần.

Trái lại nếu committed position lớn hơn position, thì toàn bộ message giữa position và committed position sẽ không được xử lý.

Kafka Consumer Group Offset Retention
Có một config trong Kafka Consume là auto.offset.reset. Nó là cấu hình chính sách được sử dụng để quyết định vị trí của message sẽ lấy về khi consume lần đầu tiên join group hoặc sau khi re-join group mà không xác định được offset hiện tại ở bất kỳ đâu trên server (Kafka or Zookeeper). Kafka hiện cung cấp 3 kiểu giá trị để quyết định chính sách auto.offset.reset .
Earliest – khi consumer lần đầu tiên join group và muốn consume toàn bộ message của topic. Consumer sẽ cấu hình auto.offset.reset = earliest.
Latest – Đây là giá trị mặc định, consumer sẽ chỉ nhận được message đến topic từ thời điểm sau khi đã subscribed thành công tới topic hoặc từ thời điểm cuối cùng (last committed offset) sau khi consumer re-joins group.
None – Consumer sẽ nhận được 1 ngoại lệ nếu không xác định được offset hiện tại khi join group. Developer cần quyết định làm gì tiếp theo.
Ok, rồi có một lưu ý nhỏ ở đây, đó là giá trị offsets.retention.minutes được cấu hình trong broker. Giá trị này quyết định sau bao nhiêu lâu thì offset sẽ bị discard, tính từ thời điểm tất cả consumer leave group hoặc từ lần commit cuối cùng nếu consumer này độc lập.
Việc này có ý nghĩa gì, giả sử consumer down trong khoảng thời gian > offset.retention.minutes thì khi consumer này re-join group với cấu hình chính sách mặc định auto.offset.reset = latest thì consumer này sẽ mất toàn bộ message trong khoảng thời gian chết và chỉ nhận được message từ sau thời điểm đã join thành công.
Từ phiên bản Kafka 2.0.0 giá trị này được thiết lập tương đương 7 ngày offsets.retention.minutes=10080. Các phiên bản trước đó chỉ có 1 ngày.
Configuring Producers
When a message is published, it gets buffered at the Producer’s side and it will wait for 30s (see config above) to fill up. spring.kafka.producer.batch-size=100000 means 100KB so if the message ingestion load is low, and the buffer doesn’t fill up with more messages to 100KB in 30s, you would expect this message.
spring.kafka.producer.linger.ms=10 is used where the ingestion load is high and the producer wants to limit send() calls to Kafka brokers. This is the duration Producer will wait before sending messages to the broker after batch is ready (i.e. after buffer is filled up to batch size of 100KB).
Solution:
Increase linger.ms to hold messages longer after the batch is ready. If more time is needed to fill the batch, increase request.timeout.ms.
Another approach: reduce batch-size, or increase request.timeout.ms, or both.
Kafka Connect
Kafka Connect là một framework cho phép stream data in/out tới Apache Kafka. Confluent Platform cung cấp sẵn một số connectors có thể dùng để stream data in/out tới 1 số hệ thống như hệ quản trị cơ sở dữ liệu quan hệ (MySQL, Oracle…) hoặc HDFS.
JDBC connector trong Kafka Connect cho phép lấy dữ liệu (source) từ cơ sở dữ liệu đẩy vào Kafka topic và đẩy dữ liệu (sink) từ Kafka topic tới cơ sở dữ liệu. Nó hỗ trợ toàn bộ các hệ quản trị cơ sở dữ liệu có implement JDBC driver như Oracle, SQL Server, DB2, MySQL, Postgres…
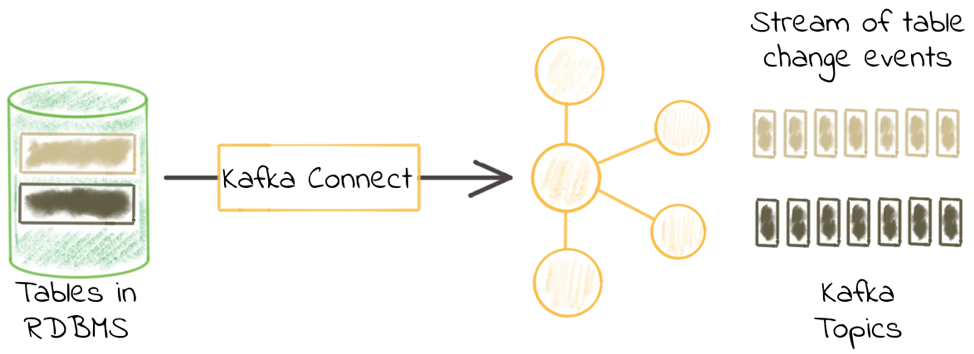
Một số khái niệm cơ bản trong Kafka Connector:
Connectors định nghĩa nguồn hoặc đích đến của dữ liệu. Một connector instance chịu trách nhiệm sao chép dữ liệu giữa Kafka và hệ thống khác. Toàn bộ classses implement hoặc sử dụng bơi connector đều được định nghĩa trong connector plugin.
Confluent Platform đã cung cấp sẵn khá nhiều Source Connector. Ví dụ: JDBC, AWS S3, HDFS… Tuy nhiên nếu cần chúng ta vẫn có thể viết thêm các connector mới. Flow cơ bản thì như hình bên dưới đây:

Về cơ bản chúng ta sẽ cần implement 2 interface là Connector và Task.
Class implement Connector sẽ chịu trách nhiệm về nguồn dữ liệu cần trích xuất còn classs implement Task chịu trách nhiệm đọc dữ liệu từ nguồn sau đó tạo các bản ghi dữ liệu để đẩy vào topic của Kafka.
Task là thành phần chính trong kiến trúc của Connector. Mỗi connector instance điều phối một nhóm các task thực thi việc đọc dữ liệu từ nguồn chỉ định. (JDBC, S3…). Bằng việc cho phép chia nhỏ job thành nhiều task, Kafka Connect cung cấp sẵn khả năng xử lý song song và mở rộng việc đọc dữ liệu thông qua cầu hình. Để làm được việc này thì trạng thái của Task được lưu trong Kafka topic là: config.storage.topic và status.storage.topic và quản lý bởi connector. Do vậy mà task có thể khởi động, tạm dừng hoặc khởi động lại bất kỳ lúc nào.
Task Rebalancing khi một connector tham gia vào cụm, những worker sẽ tự động reblance toàn bộ connector trong cụm và những task của connector đó, mục đích để đảm bão mỗi worker sẽ đảm nhận số lượng công việc giống nhau. Quá trình reblancing này cũng diễn ra khi một connecto tăng hoặc giảm số lượng task hoặc khi connector cập nhật lại cấu hình. Khi một worker chết, task sẽ tự động rebalance với những worker đang hoạt động. Trái lại một task nếu chết sẽ bị coi là trường hợp ngoại lệ, do vậy task sẽ không tự động khởi động lại mà cần được khởi động lại thông qua REST API.

Workers Connectors và task những phần việc sẽ được lập lịch để thực thi trong 1 tiến trình. Một tiến trình khi khởi chạy sẽ được gọi là 1 worker. Có 2 chế độ cho phép lựa chọn khi start worker là Standalone và Distributed.
Standalone
Distributed cung cấp khả năng mở dộng và tự động và khả năng chịu lỗi (auto failover) cho Kafka Connect. Trong mode distributed, chúng ta có thể chạy nhiều worker với chung group.id, tất cả các worker đang hoạt động sẽ tự động phối hợp cùng nhau lên lịch thực hiện task.
Converters chịu trách nhiệm chuyển đổi định dạng dữ liệu từ dạng byte sang định dạng quy định trong Connector. VD: Json, Protobuf…

Transforms
Dead Letter Queue
Cần đốt bao nhiêu calories để giảm 2kg mỗi tháng
Mỡ cơ thể (body fat) dự trữ năng lượng dưới dạng lipids. Lipids được đốt cháy để cung cấp năng lượng cho các hoạt động hàng ngày của cơ thể. Quá trình này diễn ra xuyên suốt trong 24h trong ngày kể cả khi ngủ. Lipid profile trong mỡ cơ thể chiếm ~87%. Do vậy 1kg mỡ cơ thể sẽ có 0.87kg lipid-fat. Tại sao lại chỉ có 87% vì trong mỡ cơ thể cũng bao gồm cả nước nữa.
1g lipid-fat khi sử dụng sinh ra 9 calories. Do vậy để đốt 1kg mỡ cơ thể hay 0.87kg lipid-fat thì lượng calories cần tiêu hao là:
1000 * 0.87 * 9 = 7830 calories
Ok, vậy nếu muốn giảm 1kg mỗi 2 tuần thì số calories cần thâm hụt hàng ngày sẽ là:
7830 / 14 = 559 calories (khoảng 400gram cơm trắng)
Nhẩm nhanh với một người 70kg sẽ cần chạy bộ 10km/ngày ở cường độ cao (threshold pace) để burn khoảng ~550 calories
The twelve-factor app
Disclaimer: Đây không phải bản dịch của 12-Factor. Đây là bản mô tả lại theo cách hiểu của cá nhân mình. Phiên bản đầy đủ của 12-Factor có thể truy cập tại đây: https://12factor.net/
12-Factor app là một phương pháp luận cho việc xây dựng các ứng dụng phân tán triển khai trên môi trường cloud, phân phối dưới dạng như một service. Cách tiếp cận này được pháp triển bởi Adam Wiggins, co-founder của Heroku một platform-as-a-service. Mục tiêu của Wiggin là tổng hợp các thực tiễn tốt nhất để triển khai một ứng dụng trên Heroku hoặc bất kỳ nền tảng cloud nào.
12-Factor áp dụng cho ứng dụng viết bởi bất kỳ ngôn ngữ nào, sử dụng bất kỳ sự kết hợp nào của backing services (Database, queue, memory cache…).
Code base
Ứng dụng 12-Factor chỉ có duy nhất một codebase được theo dõi bởi version control system như Git, Mercurial hoặc Subversion nhưng sẽ có nhiều bản triển khai trên nhiều môi trường khác nhau (staging, dev, production …).
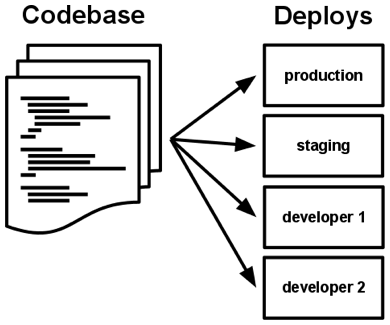
Hiểu đơn giản thì nếu bạn đang có nhiều hơn 1 codebase thì nó không phải một ứng dụng mà là một hệ thống phân tán. Nhiều ứng dụng chia sẻ code giống nhau sẽ vi phạm 12-Factor. Giải pháp ở đây là đóng gói thành thư viện và sử dụng thông qua dependency manager.
Dependencies
Một ứng dụng 12-Factor cần khai báo rõ ràng các dependencies của nó. Đã qua rồi cái thời developer cần tìm kiếm các file jars/dependencies thả vào project và cố gắng biên dịch nó. Ngày nay hầu hết các ngôn ngữ lập trình đều có hệ thống quản lý gói cho việc phân phối các thư viện hỗ trợ. Ví dụ như NPM cho NodeJS, Pip cho Python, Maven Repositories cho Java, Rubygems cho Ruby… Những thư viện này được cài đặt thông qua một hệ thống quản lý gói có thể được cài đặt trong phạm vi toàn hệ thống (được biết đến như là “site packages”) hoặc giới hạn phạm vi trong thư mục chứa ứng dụng (được biết đến như là “vendoring” hay “bundling”).
Ứng dụng 12-Factor cũng không được sử dụng bất kỳ công cụ hệ thống nào. Ví dụ: shell out đến ImageMagick hoặc curl. Mặc dù những công cụ này tồn tại trên nhiều hệ thống tuy nhiên không có gì đảm bảo rằng chúng sẽ tồn tại trên tất cả hệ thống nơi ứng dụng sẽ triển khai hoặc liệu phiên bản được tìm thấy trên hệ thống sẽ tương thích với ứng dụng. Nếu ứng dụng cần shell out đến một công cụ hệ thống thì công cụ này nên được đóng gói cùng ứng dụng.
Config
Lưu trữ cấu hình trong biến môi trường. Một cấu hình ứng dụng là mọi thứ mà có khả năng thau đổi giữa các bản triển khai (staging, production, developer….). Bao gồm:
- Đặc tả kết nối đến cơ sở dữ liệu, memcached và các dịch vụ phía sau
- Ủy quyền đến các dịch vụ bên ngoài như Amazon services hay Google cloud
- Các giá trị trên mỗi triển khai ví dụ như hostname chính thức cho bản triển khai.=
Ứng dụng lưu trữ cấu hình như hằng số trong code vi phạm 12-Factor. Trên thực tế cấu hình thay đổi tùy theo phiên bản triển khai, code thì không.
Ứng dụng 12-Factor lưu cấu hình trong biến môi trường (thường viết ngắn gọn là env vars hoặc env ). Các biến môi trường dễ dàng thay đổi giữa các triển khai mà không phải thay đổi code, không giống như tệp cấu hình, chúng chỉ có nguy cơ nhỏ khong may bị đánh dấu trong code repo, và cũng không giống như tệp cấu hình tùy chỉnh, hay các cơ chế cấu hình khác ví dụ Java System Properties, chúng là theo chuẩn không thể biết của ngôn ngữ lập trình và hệ điều hành.
Backing services
Một backing services là bất kỳ một service nào mà ứng dụng này sử dụng qua mạng như một phần của hoạt động bình thường. Backing services bao gồm các local service hoặc từ bên thứ ba như cơ sở dữ liệu, message queues, cache services.
Mỗi một backing service là một resource. Ví dụ: một cơ sở dữ liệu MySQL là một resource, hai cơ sở dữ liệu MySQL (shardung at the application layer) được xác định là 2 resources riêng biệt. Ứng dụng 12-Factor coi những cơ sở dữ liệu này như những tài nguyên đính kèm, giảm thiểu sự phụ thuộc của chúng với phiên bản triển khai của ứng dụng.
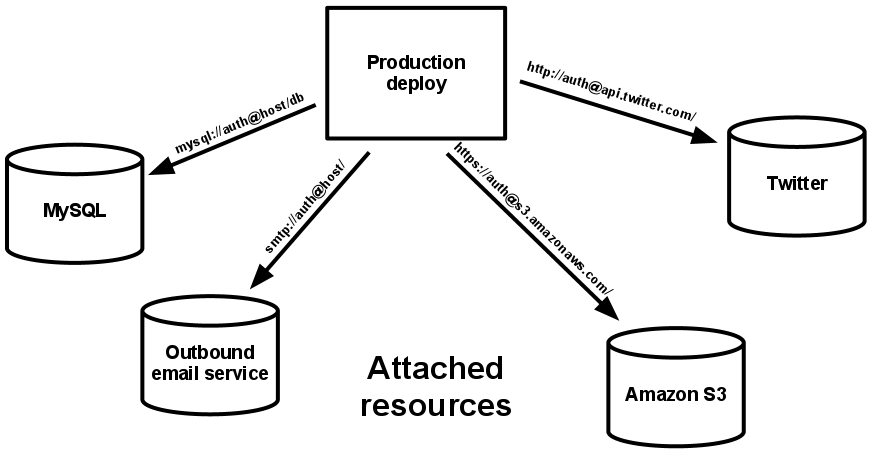
Resource có thể gắn vào hoặc tách ra từ các bản triển khai nếu muốn. Ví dụ nếu CSDL của ứng dụng bị lỗi, người quản trị có thể chuyển sang một CSDL khác mà không cần thay đổi bất kỳ dòng code nào.
Build, release, run
Ứng dụng 12-Factor có 3 giai đoạn chính: build, release, run.
- Build là quá trình compile code từ VCS và đóng gói thành một phiên bản ứng dụng.
- Giai đoạn release là khi kết hợp bạn build có được từ trước cùng với các cầu hình cần thiết của ứng dụng. Sẵn sàng cho việc triển khai trên môi trường thực tế.
- Giai đoạn run là khi ứng dụng đã triển khai và hoạt động trên môi trường thực tế.
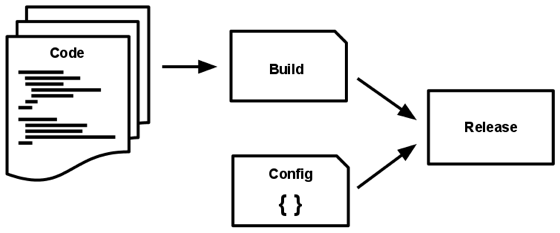
Mọi bản phát hành luôn có một ID duy nhất. Có thể sử dụng timestamp phát hành như 2019-21-03-16:11:03 hoặc một số tự nhiên tăng dần như v1001. Bất kỳ thay đổi nào đến bản build (ví dụ: bug fixes) cũng cần một bản release mới.
Processes
Thực thi ứng dụng như một hoặc nhiều tiến trình phi trạng thái. Các tiến trình theo 12-Factor thì không có trạng thái và không chia sẻ bất kỳ thứ gì. Bất kỳ dữ liệu cần được duy trì phải được lưu ở một backing service, thông thường là CSDL.
Dữ liệu phiên làm việc (session state) nên được lưu trữ thông qua một backing service có time-based expiration. Ví dụ: Hazelcast, Redis, Memcached
Port binding
Ứng dụng 12-Factor không bao gồm web server mà thay vào đó sử dụng giao thức HTTP như một service bằng cách binding đến một cổng và lắng nghe request đến cổng đó. Điều này đảm bảo ứng dụng hoàn toàn khép kín và không dựa vào một web server cụ thể.
HTTP không phải là dịch vụ duy nhất có thể sử dụng port binding. Hầu như bất kì kiểu server software nào cũng có thể chạy thông qua tiến trình binding port và chờ request đến cổng này. Ví dụ: Redis, Memcached
Concurrency
Trong ứng dụng 12-Factor các loại công việc khác nhau được xử lý bởi các tiến trình khác nhau. Các tiến trình trong ứng dụng 12-Factor lấy các gợi ý mạnh mẽ từ mô hình tiến trình của unix cho các dịch vụ daemon đang chạy. Sử dụng mô hình này, nhà phát triển có thể kiến trúc ứng dụng của họ để xử lý các workload đa dạng bằng cách gán mỗi kiểu công việc cho một kiểu tiến trình. Ví dụ, các HTTP request có thể được xử lý bởi các tiến trình web, và các task (nhiệm vụ) chạy nền thời gian dài được xử lý bởi một tiến trình worker.
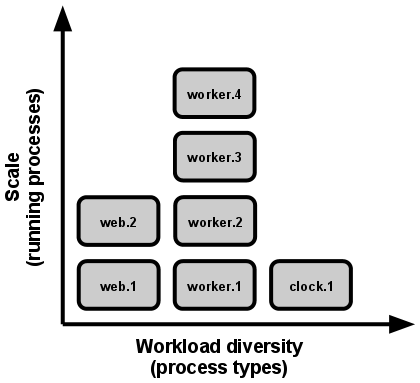
Về cơ bản ứng dụng 12-Factor phải có khả năng mở rộng theo chiều ngang, áp dụng các tiến trình phi trạng thái, không chia sẻ ứng dụng có thể mở rộng liên tục.
Disposability
Tiến trình của ứng dụng 12-Factor cần có tính sẵn sàng có nghĩa là có thể bậ hặc tắt khi có thông báo tại một thời điểm nào đấy. Điều này dễ dàng cho việc mở rộng, triển khai nhanh chóng khi thay đổi code hoặc cấu hình.
Các tiến trình nên cố gắng giảm tối đa thời gian khởi động. Lý tưởng là một tiến trình mất vài giây tính từ lúc khởi động đến khi sẵn sáng nhận request và job.
Dev/prod parity
Tính tương đồng giữa các phiên bản. Giữ môi trường development, staging và product ion giống nhau nhất có thể. Trong lịch sử, đã có những lỗ hổng thực tế giữa development và production. Ứng dụng 12-Factor được thiết kế để triển khai liên tục bằng việc giảm thiểu khoảng cách giữa development và production.
- Developer có thể viết code và triển khai ngay sau đó.
- Developer viết code chịu trách nhiệm deploy và theo dõi trong môi trường production.
- Giữa môi trường development và production giống nhau nhất có thể. Ví dụ sử dụng docker.
Logs
Theo 12-Factor log là một luồng các sự kiện được sắp xếp theo thứ tự thời gian thu thập từ các luồng đầu ra của toàn bộ các tiến trình đang chạy và các backing services. Quá trình này diễn ra liên tục miễn là ứng dụng còn đang hoạt động.
Một ứng dụng 12-Factor không chịu trách nhiệm định tuyến hoặc lưu trữ dòng dữ liệu đầu ra của nó. Nó không cố gắng ghi hay quản lý các logfile. Thay vào đó mỗi tiến trình đang chạy sẽ ghi trực tiếp luồng sự kiện của nó, không sử dụng bộ đệm (unbuffered) tới stdout.
Developer có thể view log trên terminal hoặc điều hướng tới log collector. Ví dụ: Logplex, Fluentd, Logstash…
Admin processes
Chạy các task admin/management như các tiến trình one-off (một lần).
Processes formation là một loạt các tiến trình mà được sử dụng để thực hiện công việc thường lệ của app (ví dụ xử lý các web request) khi nó chạy. Các nhà phát triển sẽ thường thực hiện các task mang tính quản trị hoặc bảo trì cho ứng dụng. Ví dụ:
- Database migration, backup.
- Run shell console
- Run script
Chuẩn hóa vector
Ta có vector x và y. Phép nhân hoặc chia làm thay đổi chiều dài của vector mà không ảnh hướng đến phương và hướng. OK, câu hỏi ở đây là làm thế nào chúng ta biết được chiều dài của một vector? Nếu biết trước các thành phần (x và y).
Hiểu được cách tính chiều dài (hay còn gọi là độ lớn) của vector là vô cùng quan trọng và hữu ích.
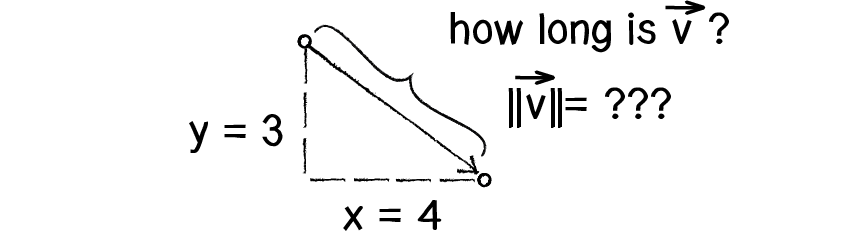
Chiều dài hoặc độ lớn của vector v được ký hiệu là

Hình vẽ trên cho thấy mũi tên nối 2 điểm x,y tạo thành một tam giác vuông. Các cạnh bên là các thành phần với cạnh huyền chính là mũi tên. Với tam giác vuông này chúng ta có thể áp dụng công thức của nhà toán học Pythagoras mô tả mối quan hệ giữa các cạnh và cạnh huyền trong một tam giác vuông.
Trong tam giác vuông, bình phương cạnh huyền bao giờ cũng bằng tổng bình phương hai cạnh còn lại.
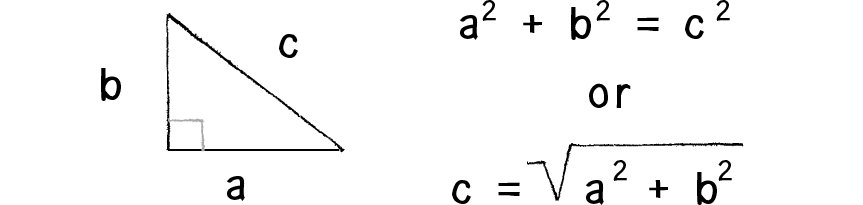
Áp dụng công thức trên ta có mã hiện thực như sau:
/**
* Compute magnitude of vector
*/
public double length() {
return Math.sqrt(dX * dX + dY * dY);
}
Việc tính toán được độ lớn của vector mở ra nhiều khả năng, đầu tiên là chuẩn hóa vector. Trong một số trường hợp ta chỉ quan tâm đến hướng của vector đó mà bỏ qua độ lớn của nó. Với trường hợp như vậy ta thay đổi độ lớn của vector đó về 1. Những vector có tính chất như trên ta gọi chúng là vector đơn vị.
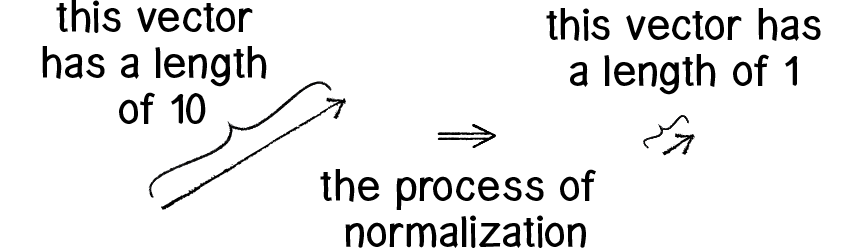
Ta chuẩn hóa vector bằng cách chia mỗi thành phần cho độ lớn cuả nó.
/**
* Normalize a vectors length....
*
* @return normal vector
*/
public Vector normalize() {
Vector vn = new Vector();
double length = Math.sqrt(this.dX * this.dX + this.dY * this.dY);
if (length != 0) {
vn.dX = this.dX / length;
vn.dY = this.dY / length;
}
return vn;
}
Tại sao khi vận động mạnh bạn lại có thể bị đau cơ?
Trong phần lớn các trường hợp đau cơ, nguyên nhân chính là do sự tích tụ acid lactic trong cơ. Khi đó, pH của các tế bào cơ thay đổi và toàn bộ cơ bị ảnh hưởng. Đau cơ làm cho chúng ta mệt mỏi, ngại vận động và chỉ muốn nghỉ ngơi, nằm ngủ.
Vậy tại sao acid lactic lại bị tích tụ? Khi chúng ta hoạt động mạnh, cơ thể không cung cấp đủ O2 cho các tế bào cơ hô hấp hiếu khí tạo ATP dùng trong quá trình co cơ. Để khắc phục vấn đề này, các tế bào cơ lên men lactic mà không cần O2, cung cấp lượng ATP cần thiết trong khi máu chưa đưa được O2 đến cơ. Kết quả là acid lactic bị tích tụ trong cơ.
Nhưng cơ thể con người là một hệ thống thông minh và hoạt động hiệu quả! Acid lactic tích tụ trong cơ được vận chuyển về gan và chuyển hoá lại thành glucose. Toàn bộ chu trình chuyển hoá này có tên là chu trình Cori.
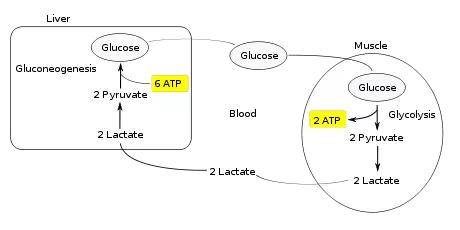
Nếu lượng acid lactic trong cơ bị tích tụ quá nhiều, không được chuyển hoá (do các nguyên nhân khác nhau) sẽ gây ra các cơn đau khủng khiếp. Muốn tránh được điều này, cách tốt nhất là bạn nên tập thể dục đều đặn. Việc tập thể dục sẽ tăng cường hoạt động của hệ hô hấp và hệ tuần hoàn, qua đó làm tăng lượng O2 máu đưa đến cơ, giảm lượng acid lactic tích tụ.
2 người tìm ra chu trình Cori là Gerty Cori và Carl Cory, cả 2 cùng nhận giải Nobel năm 1947 nhưng không phải là do khám phá ra Cori cycle.
